

HTTP🍔Frontend/웹 관련 지식2021. 6. 24. 14:31
Table of Contents
HTTP (Hypertext Transfer Protocol)
- HTTP는 서버와 클라이언트가 인터넷상에서 데이터를 주고받기 위한 프로토콜(Protocol)이다
- HTTP는 HTML 문서와 같은 리소스들을 가져올 수 있도록 해주는 프로토콜이다.
- 프로토콜은 컴퓨터 내부에서, 또는 컴퓨터 사이에서 데이터의 교환 방식을 정의하는 규칙 체계이다.
- HTTP는 웹에서 이루어지는 모든 데이터 교환의 기초이며, 서버-클라이언트 프로토콜이기도 하다.
- 서버-클라이언트 프로토콜이란 (보통 웹브라우저인) 수신자 측에 의해 요청이 초기화되는 프로토콜을 의미한다.
HTTP 특징
1. 클라이언트-서버 구조
- 클라이언트가 서버에 요청을 보내면 서버는 그에 대한 응답을 보내는 클라이언트-서버 구조로 이루어져 있다.
- Request/Response 구조
request/response
- 브라우저인 클라이언트에 의해 전송되는 메시지를 requests(요청)이라고 부른다.
- 그에 대한 서버의 응답으로 전송되는 메시지를 reponses(응답)라고 부른다.
2. 비연결성 - Connectionless 프로토콜
- HTTP 1.0을 기준으로 HTTP는 연결을 유지하지 않는 모델!
- 클라이언트와 서버가 한번 연결을 한 후, 클라이언트의 요청에 서버가 응답을 하고나면 연결을 끊어버리는 성질이다
장점
- HTTP는 인터넷 상에서 불특정 다수의 통신 환경을 기반으로 설계되어 있다!
- 만약 서버가 다수의 클라이언트와 연결을 유지하면 많은 리소스가 소모된다 → 다른 사용자가 리소스를 사용하지 못할 수도 있음
- 클라이언트가 요청을 하지 않고 연결이 유지되어 있다면 자원이 소모!
- 즉, Connectinoless 성질을 이용해 연결을 유지하기 위한 리소스를 줄이면 서버의 자원을 효율적으로 사용할 수 있다!
단점
- 연결이 끊어짐에 따라 다시 연결될 때 TCP/IP 연결을 새로해야 하므로 3-way handshake에 따른 시간이 추가된다!
- 예를 들어 웹 브라우저를 이용해서 요청을 하면 HTML/Javascript/CSS/이미지 등 수많은 자원을 보낼 때마다 연결을 끊고 다시 연결!
- 서버가 클라이언트를 기억하고 있지 않으므로 동일한 클라이언트의 요청이 일어날 때마다 새로운 연결의 시도와 해제 과정을 반복하게 되어서 많은 오버헤드가 발생한다!
Keep-alive
- 비연결성의 단점은 HTTP의 Keep-alive으로 해결할 수 있다
- 서버는 클라리언트와 맺은 연결을 특정 시간동안 유지한다.
- HTTP 1.1에서는 디폴트로 지원하는 기능이며 헤더도 필요하지 않다!
- HTTP 1.0을 기준으로 클라이언트와 서버 사이에 한번 연결이 발생하고 요청에 대한 응답이 끝나면 연결이 끊어졌다.
- 만약 HTTP 1.0 기반에서 Keep-alive 기능을 사용하길 원하면 클라이언트는 아래처럼 서버에게 HTTP 요청 시, 요청 메시지 헤더에 아래와 같은 헤더를 추가한다.
Connection: keep-alive- 서버의 응답 메세지 Keep-alive 헤더는 다음과 같이 설정할 수 있다!
- timeout=4 → 4초간 연결을 유지
- max=50 → 50회의 요청 내에 연결 유지 시간 갱신을 허용
- 만약 4초내에 재요청이 들어오면 max값은 99가 된다!
- 즉, 최대 4 x 50 = 200초동안 연결을 유지할 수 있다!
Keep-Alive: timeout=4, max=50
- 위와 같이 Keep-alive를 사용하는 것은 완벽한 해결책이 아니다! 서버가 바쁜 상황이면 프로세스의 수가 기하급수적으로 늘어나서 메모리를 많이 사용할 수 있다
3. 무상태 - Stateless 프로토콜
- HTTP에서 요청에 대한 응답이 발생하면 연결이 끊어지는 특성 때문에 HTTP에서 서버가 클라이언트의 상태를 보존하지 않는 특징이다.
- 서버는 클라이언트의 세션 관리를 하지 않으므로 서버 확장에 용이하다!
- 클라이언트의 이전 상황을 알 수 없는 특징 때문에 정보를 유지하기 위해 Cookie와 같은 기술이 등장했다.
- 사용자가 매번 새로운 인증과정을 거쳐야함 ㅠㅠ → 쿠키/세션으로 해결!
- 쿠키/세션에 관한 정보는 아래에서 자세하게 알아보자↓↓↓
- https://duckgugong.tistory.com/285
쿠키🍪/캐시/세션+jwttoken
HTTP의 Stateless/Connectionless 프로토콜 Statelss 프로토콜 클라이언트의 상태에 대한 정보를 가지지 않는 서버 처리 방식 클라이언트와 쿠키
duckgugong.tistory.com
HTTP 구조 (Requests)
- HTTP는 requests는 startline, header, body로 이루어져 있다.

startline
HTTP의 startline은 세가지 요소로 이루어져있다.
- HTTP 메서드(GET, PUT, POST 등)로 서버가 수행해야 할 동작을 나타낸다.
- URL, 또는 프로토콜, 포트, 도메인 등 요청 타겟이 나타난다.
- HTTP의 버전이 들어간다.
example
GET /duck.html?a=duck HTTP/1.1POST http://localhost:8080/duck HTTP/1.1Header

HTTP 헤더는 클라이언트와 서버가 요청 또는 응답으로부터 부가적인 정보를 전송할 수 있도록 한다.
- Request Header: 패치될 리소스나 클라이언트 자체에 대한 자세한 정보를 표기한다.
- Host: 요청이 전송되는 타겟 호스트 URL 주소
- User-Agent: 요청을 보내는 클라이언트의 정보
- Accept: 해당 요청이 받을 수 있는 응답 body의 데이터 타입 정보
- General Header: 요청과 응답에 모두 적용되지만 body에서 최종적으로 전송되는 데이터와는 관련이 없다.
- Entitiy Header: 컨텐츠의 길이나, body의 데이터가 어떤 타입인지 명시한다.
- content type: 헤더부분에 명시된 content type은 body의 데어타가 어떤 타입인지를 명시한다.
그러므로, content type은 request에도 명시될 수 있고, response 시에도 명시될 수 있다.
html에서 form 방식으로 전송되는 데이터 타입은 x-www-form-url-encoded 방식이다. key=value&key2=value2 이런 형식으로 전송되는 타입이다.
json 형태로 보낼때는 application/json 타입으로 정의한다.
- content type: 헤더부분에 명시된 content type은 body의 데어타가 어떤 타입인지를 명시한다.
Body
- 모든 요청에 대해서 Body가 들어가있지는 않다. GET, HEAD DELETE처럼 리소스를 가져오는 요청은 보통 본문이 필요없다.
- 보통 HTML 폼 데이터를 포함하는 POST 요청일 경우에 Body에 데이터를 담아서 전송한다
HTTP 구조(Responses)
- HTTP는 responses는 startline, header, body로 이루어져 있다.
startline
- 요청의 결과를 알려주는 상태코드(status)가 나타난다.
- https://datatracker.ietf.org/doc/html/rfc2616#section-6.1.1
- 개발시에 상태코드를 보고 무슨 문제인지 알 수 있어야 한다. 상태코드가 오류가 나면 대부분 개발자의 코드에 찍히는 것이 아니라 브라우저가 에러를 처리하기 때문이다.
Header
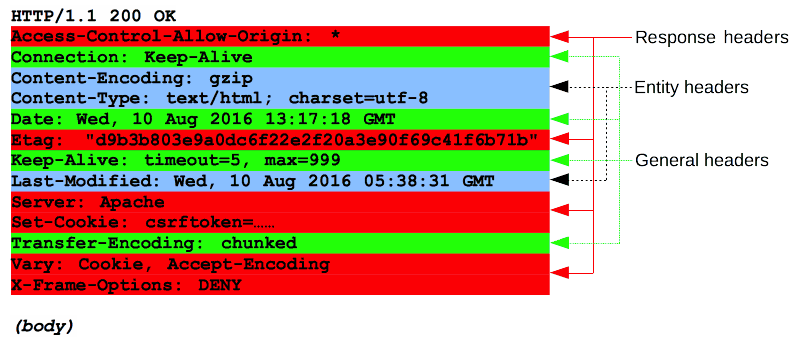
- HTTP 요청의 헤더와 비슷하다.
- User-Agent 대신 Server헤더가 사용된다.
Body
- 전송하는 데이터가 없으면 비어있다.
- HTTP 요청 헤더와 동일하다.
HTTP 작동방식
- 클라이언트와 서버가 계속 연결된 형태가 아니기 때문에 클라이언트와 서버 간의 최대 연결 수보다 훨씬 많은 요청과 응답을 처리할 수 있다.
- 연결을 끊어버리기 때문에, 클라리언트의 이전 상황을 알 수 가 없다. 이러한 특징을 무상태(Stateless)라고 말한다.
- 이러한 특징 때문에 정보를 유지하기 위해 Cookie와 같은 기술이 등장했다.
URI vs URL
URI
- 인터넷 상의 자원의 위치이다.
- 모든 자원을 표기하기 위한 규격
http://www.duck.com/htmlURL
- URI의 부분집합으로 프로그램의 실행 경로, 파라미터 등을 포함함 형태까지를 말한다.
google.com/search?q=아이폰&sourceid=chrome&ie=UTF-8HTTP 요청 메서드
GET
- URI 형식으로 웹 서버측 리소스를 요청한다.
- 서버로 정보를 제출하기도 한다.
- 쿼리 파라미터를 사용해서 해당하는 본문 형식을 받아온다.
- 서버에 파라미터를 날릴 때, url에 파라미터가 찍힌다.
- URL 뒤 ? 다음에 key=value&key=value… 이런식으로 key=value를 &로 연결해서 데이터를 보낸다.
이것을 query 파라메터라고 한다.
google.com/search?q=아이폰&sourceid=chrome&ie=UTF-8POST
- 클라이언트에서 서버로 정보를 제출한다.
- 요청 데이터를 HTTP Body에 담아서 웹 서버로 전송!
PUT
- 데이터를 생성. (POST와 비슷한 기능이다.)
DELETE
- 서버에서 데이터 삭제 요청
GET VS POST (중요)
- GET과 POST의 가장 큰 차이점은 GET은 request 시에 Header만 존재하고 Body가 없다는 것이다.
그러므로 URL 뒤 ? 다음에 key=value&key=value… 이런식으로 key=value를 &로 연결해서 데이터를 보낸다.
이것을 query 파라메터라고 한다. - GET은 Query Parameter를 사용하고 Post는 body에 데이터를 보내야 한다고 알고 있다면 그것은 잘못된 생각이다.
- GET은 Request시에 body에 데이터를 보낼수가 없다. 그래서 GET은 Query Parameter 밖에 사용할 수가 없다.
하지만 Post는 body에 데이터를 담아서 보낼수 있으므로 body로 데이터를 보내지만 그렇다고 Query Parameter로 데이터를 보낼수 없는것이 아니다.
GET 방식으로 데이터를 전달하는 방법
- 쿼리 파라미터를 사용해서 데이터를 보낸다!
- ? : 여기서부터 전달할 데이터가 작성된다는 의미.
- & : 전달할 데이터가 더 있다는 뜻이다.
- 예시) google.com/search?q=아이폰&sourceid=chrome&ie=UTF-8
- 위 주소는 google.com의 search 창구에 다음 정보를 전달합니다!
q=아이폰 (검색어) sourceid=chrome (브라우저 정보) ie=UTF-8 (인코딩 정보)
++HTTP란?
- 아래 블로그를 참고하자!!
- https://rachel-kwak.github.io/2021/03/08/HTTPS.html
HTTPS란? (동작방식, 장단점)
몇 년 전만 해도 전자 상거래 페이지가 있는 웹사이트에서만 HTTPS를 사용하고 있었다. 그러나 2014년, 구글에서 HTTPS를 사용하는 웹사이트에 대해서 검색 순위 결과에 약간의 가산점을 주겠다고
rachel-kwak.github.io
'Frontend > 웹 관련 지식' 카테고리의 다른 글
| JWT TOKEN🍗 (0) | 2022.05.23 |
|---|---|
| 쿠키🍪와 세션/캐시 + 웹 스토리지 (0) | 2022.05.17 |
| Proxy (Forward, Reverse) (0) | 2022.02.15 |
| 서버와 서버리스 (0) | 2021.08.22 |
| DOM (1) | 2021.07.12 |
@덕구공 :: Duck9s'
주니어 개발자에욤
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!


